How do we solve Equilibrium?
In this notebook, we will give a brief overview of how we treat the 3D ideal MHD equilibrium as an optimization problem. First of all, here are the ideal MHD equations,
We will use flux coordinates \((\rho, \theta, \zeta)\) for the derivations. Then, we can write a general magnetic field in contravariant form as,
We will explain the covariant and contravariant basis vectors in detail in another notebook. For the sake of this notebook, you can just think of them as a curvilinear coordinate system.
Assuming the flux surfaces are nested, we conclude that there is no radial component of the magnetic field, so \(\mathbf{B}\cdot\nabla \rho=0\) and the \(B^{\rho}\) term drops out. Applying \(\nabla \cdot \mathbf{B}=0\),
\(\sqrt{g}\) is the determinant of the Jacobian matrix. Hence,
Applying the condition of total toroidal and poloidal flux (for the latter use the definition of \(\iota = \cfrac{\partial\psi_P/\partial\rho}{\partial\psi_T/\partial\rho}\)), we get,
The above equation states that for given functions \(R(\rho, \theta, \zeta), Z(\rho, \theta, \zeta)\) and \(\lambda(\rho, \theta, \zeta)\), the magnetic field can be found. We will use this fact and transform solving the 3D ideal MHD equations into a flux surface shape optimization problem. To describe the surfaces and \(\lambda\), we will use Fourier-Zernike basis. In DESC, we have a dedicated FourierZernikeBasis class for these. Then, the spectral parametrized functions become,
In theory, by increasing the resolutions L, M and N, we can parametrize any surface since the chosen polynoms are orthogonal.
Optimization Problem
We can write the force error minimization as follows,
In DESC, we use \(\bar{x}\) which includes both optimization and constraint parameters since they are useful for general stellarator optimization problem (i.e. allowing last closed flux surface, LCFS, to change to get better QA/QH etc.). However, the objectives are function of \(\mathbf{x}\) only.
For pure force minimization problem, all of our constraints are linear and can be written by \(\mathbf{A\bar{x}=b}\) where \(\mathbf{A}\) is the constraint matrix and \(\mathbf{b}\) is the target for constraints, but in general, we can have some non-linear constraints too. DESC offers different initialization methods, but we will focus on LCFS boundary condition. In addition to boundary shape, we need to give pressure profile and iota or current profile.
Constrained to Unconstrained Optimization
The problem formulated above is a constrained optimization problem. Ideally, we want to have unconstrained optimization. For this setup, it can be done by first computing the null-space of \(\mathbf{A}\), thus we have,
This approach requires us to solve \(\mathbf{Ax_{particular}=b}\) and find the null-space only once at the beginning, then the actual optimization iterations can use unconstrained \(y\). From linear algebra, it is known that null-space can be found by singular value decomposition (SVD). Moreover, once we get the SVD, it is significantly easier to solve linear system \(\mathbf{Ax_{particular}=b}\). All of these steps are implemented in
desc.objectives.utils.factorize_linear_constraints function.
In the code, we refer to y as reduced state vector or x_reduced. factorize_linear_constraints function will also provide project and recover methods that enables going back and forth between \(\bar{x}\) and x_reduced.
Iterations in a nutshell
DESC offers different optimizers. Unless the users specifies another optimizer, the default one is least square with trust region, in the code lsqtr. Here, we will show you briefly how a gradient descent based method works. First, for convenience, the objective function will be called f(x) (here the x is not strictly one of the x’s defined above),
Taylor expanding the function a close distance \(\Delta x\) around point x,
For multivariable functions, \(\cfrac{d\mathbf{f}}{d\mathbf{x}}\) becomes a matrix known as the Jacobian. We can also represent it with gradient, so \(\cfrac{d\mathbf{f}}{d\mathbf{x}}=\nabla \mathbf{f}= \mathbf{J}\),
The details of getting the Jacobian will be explained in Derivatives notebook. Returning back to the Taylor expansion, if we neglect higher order terms (in practice we usually do due to the computational problems thats comes with Hessians but there are several implementations in DESC that uses second or higher order terms i.e. perturbations, fmintr etc.),
In Newton methods, at each iteration we are trying to find a \(\Delta x\) such that we will minimize \(||f(x+\Delta x)||^2\). This can be satisfied by,
The aim at the end of iteration is to find the new point \(x+\Delta x\) which gives lower value of the objective function. We can find the step size as follows,
The above equation introduced \(\mathbf{J}^T\) to prevent abuse of notation of the inverse. For non-square matrices, the inverse is not defined, one can only find left or right inverses which are called pseudo-inverse. Though, one can write \(\Delta x = -\mathbf{J}^{\dagger}\mathbf{f}(x)\) by specifying that \(\mathbf{J}^{\dagger}\) is the left inverse. Moving forward, we see that the inverse of \(\mathbf{J}^T\mathbf{J}\) is needed which is computationally heavy and inaccurate.
Instead, we will use matrix decomposition again. This time QR decomposition will be used (the user can change the decomposition type to “SVD” or “Cholesky” by supplying tr_method option to the optimizer). The reason for changing method is that this operation will be conducted every single iteration of the optimization, thus it needs to be fast. Although SVD is very accurate, compared to QR, it is slower. Once a QR decomposition is found, the step size can be found as follows,
The last equation can be rewritten as,
Since \(R\) is known to be upper triangular, the above linear system can be solved by backward substitution efficiently.
The given procedure finds a step size but it could be too large or small which causes optimizer to diverge or last very long. Therefore, we use a method called trust-region to alter the step accordingly.
Trust Region Method
Trust region method finds a new descent direction and a step size for \(\Delta x\) such that it satisfies \(||\Delta x||\leq r_{tr}\) where \(r_{tr} \in \mathbb{R}\) is a positive number. The optimization problem for this case is,
If the basic Newton step that is found from the previous section does not satisfy the constraint, we add a regularization term to the objective. This is known as Tikhonov regularization and similar to Levenberg-Marquardt method. Then, the trust-region subproblem becomes,
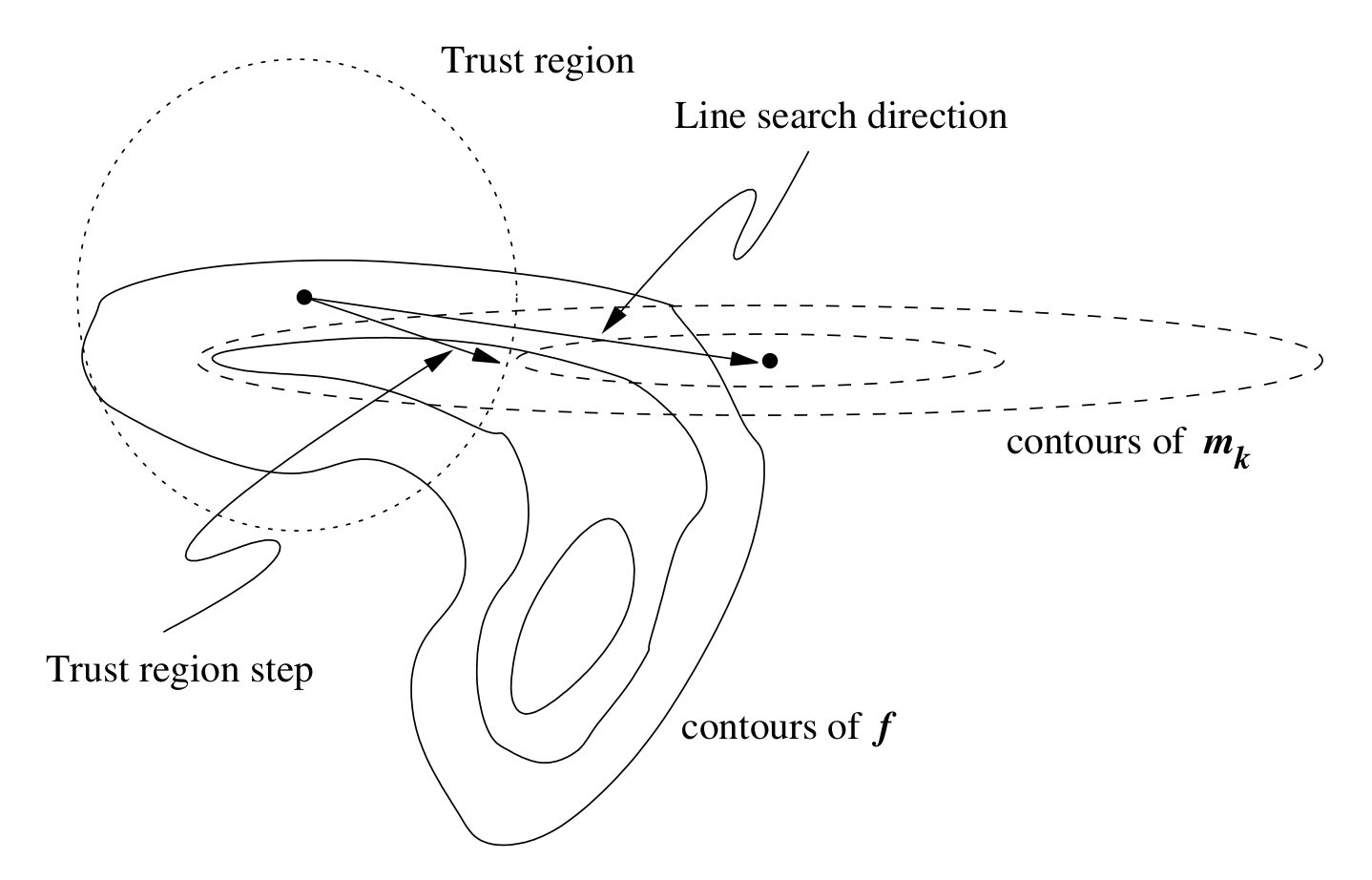
We won’t go into the details of trust region method but interested readers can refer to “Nocedal & Wright, Numerical Optimization, Chapter 4” for more information on this method.
We provide different functions to solve this subproblem which are all located in the desc/optimize/tr_subproblem.py. Some of them are based on QR decomposition (default), SVD and Cholesky decomposition. It has been observed that Cholesky is the fastest among them but doesn’t give accurate enough results for our case (Jacobian matrix is ill-conditioned). For multiple iterations QR is faster than SVD. We specifically mention that QR is “on average” faster than SVD because while SVD algorithm
requires only 1 matrix decomposition in the root finding, QR method decomposes the matrix every single step of the root finding in \(\alpha\). Usually, only the first 2-3 subproblems takes longer to solve in QR compared to SVD, but for a long optimization following iterations are significantly faster.
Solving Trust Region Problem with QR
Briefly, for the QR decomposition algorithm, we expand the regularized objective function to get the following,
Then,
We solve the linear system with different values of \(\alpha\) (treated as root-finding problem) until the norm of the step \(\Delta x\) is close enough to \(r_{tr}\).
Solving Trust Region Problem with SVD
For SVD, the most computationally expensive part is the single SVD, but then the root finding is very simple.
Since \((\Sigma^T\Sigma + \alpha \mathbb{I})^{-1}\) is just the inverse of the diagonal entries, once the SVD decomposition is known \(\Delta x\) can be computed for different values of \(\alpha\) almost without any expense.
Note: DESC offers many other optimizers, check Optimizers Supported page for details. Trust region method or lsq-exact is the default for most of the optimization problem solved in DESC.
Initial Guess
The equilibrium solution is explained above. Lastly, it is useful to show how we get the initial guess for the optimization. When an equilibrium is initialized by a LCFS, at the end of the __init__ method, we call set_initial_guess which provides initial \(R_{lmn}\) and \(Z_{lmn}\) coefficients. This is done by scaling the given LCFS down around its central axis. \(\lambda_{lmn}\) coefficients are initialized by 0.
[1]:
import sys
import os
sys.path.insert(0, os.path.abspath("."))
sys.path.append(os.path.abspath("../../../"))
import desc
import numpy as np
from desc.equilibrium import Equilibrium
from desc.plotting import plot_surfaces, plot_comparison, plot_3d
from desc.grid import LinearGrid, ConcentricGrid
import plotly.graph_objects as go
import plotly.io as pio
# This ensures Plotly output works in multiple places:
# plotly_mimetype: VS Code notebook UI
# notebook: "Jupyter: Export to HTML" command in VS Code
# See https://plotly.com/python/renderers/#multiple-renderers
pio.renderers.default = "plotly_mimetype+notebook"
DESC version 0.12.3+186.g001cfa33c.dirty,using JAX backend, jax version=0.4.35, jaxlib version=0.4.35, dtype=float64
Using device: CPU, with 5.62 GB available memory
[2]:
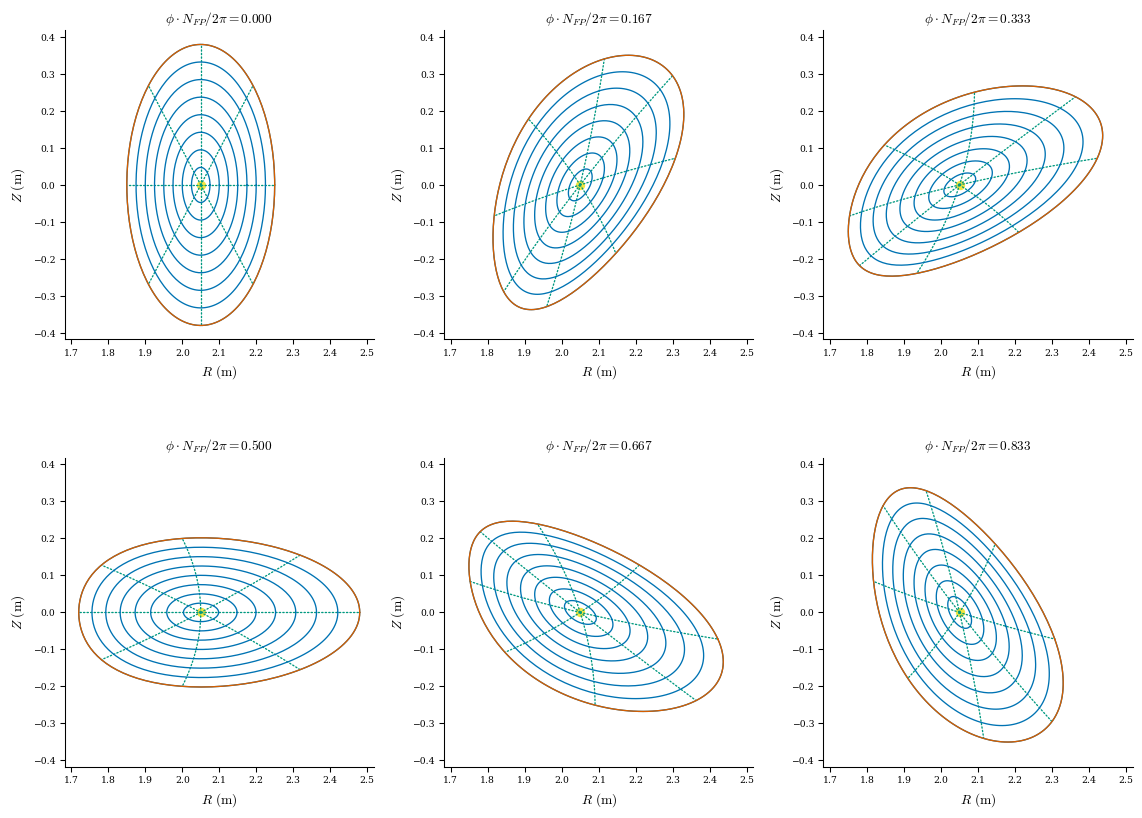
# for this example, we will use the LCFS of the ATF from DESC examples
lcfs = desc.examples.get("ATF").get_surface_at(rho=1)
# initialize the equilibrium object with the LCFS
eq = Equilibrium(surface=lcfs)
# plot flux surfaces of the initial guess
plot_surfaces(eq);
[3]:
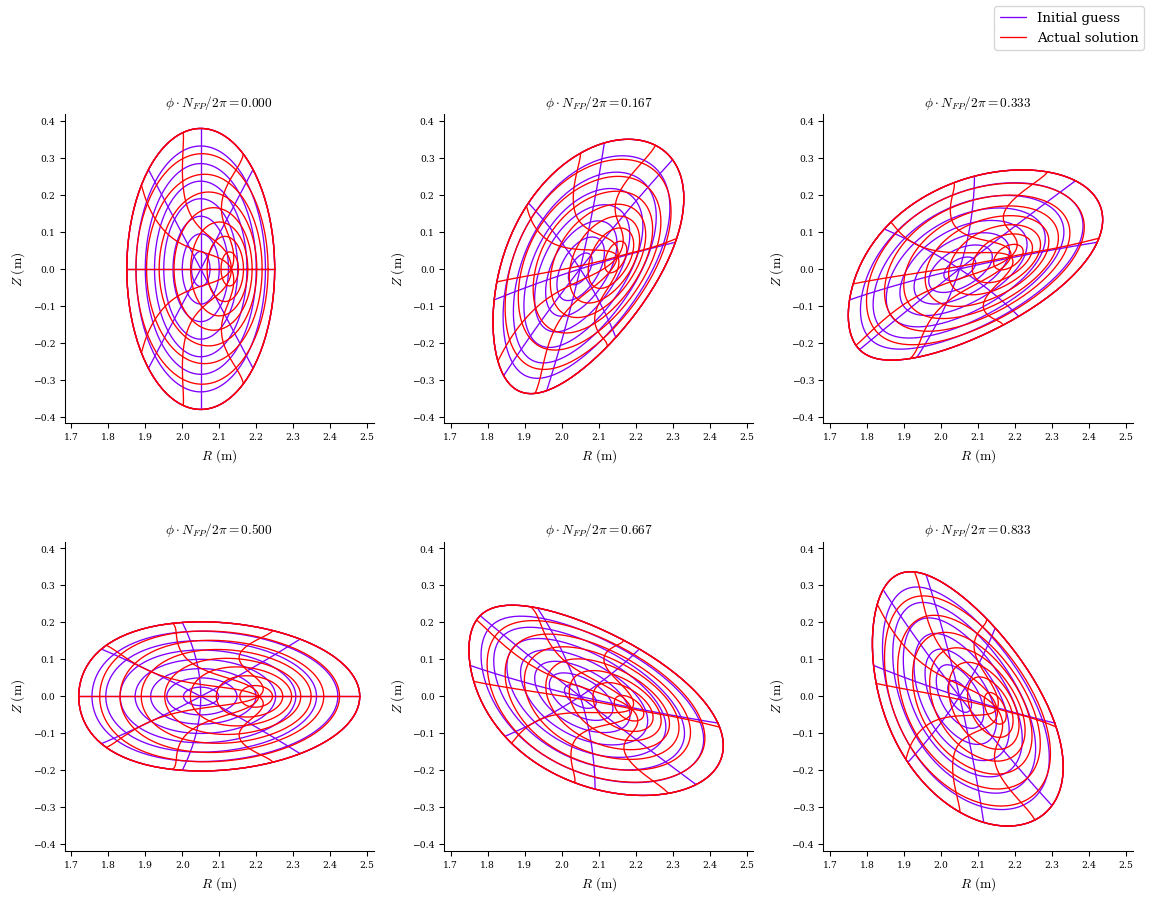
eq_solved = desc.examples.get("ATF")
# we can also compare the initial guess with the actual solution
plot_comparison(eqs=[eq, eq_solved], labels=["Initial guess", "Actual solution"]);
Computational Domain
The toroidal domain that we are working on has a couple symmetry properties that allow us to reduce the computational domain. These are
Number of field periods symmetry (NFP)
Stellarator symmetry (up-down symmetry)
Number of field periods symmetry is basically an integer quantifying how many times a certain region repeats itself along the toroidal direction. If flux surface shapes are known for a toroidal angle of \(2\pi/NFP\) then, the full \(2\pi\) can be found simply by repeating it.
Stellarator symmtry can be shown as,
Let’s see these in effect visually! Here, we will use ARIES-CS equilibrium with \(NFP\)=3. First, apply the \(NFP\) symmetry,
[4]:
eq = desc.examples.get("ARIES-CS")
grid = LinearGrid(
rho=1,
theta=np.linspace(0, 2 * np.pi, 60),
zeta=np.linspace(0, 2 * np.pi / eq.NFP, 60),
sym=False,
)
fig = plot_3d(eq, "|B|", grid=grid)
fig = plot_3d(eq, "|B|", alpha=0.2, fig=fig)
fig.show()
The full toroidal domain, shown transparent, is formed by repeating the solid part 3 times along the toroidal direction.
Now, we will consider stellarator symmetry. This symmetry property will help us reduce the computational domain further by eliminating the redundant grid points from the computation by using the 3 identities given above that makes them duplicates of some other points. One can choose a range of \(\theta, \zeta\) to satisfy those. However, it is not unique, and the choice can be different for other codes. In DESC, if the equilibrium of interest has stellarator symmetry, we only consider \(\theta\in[0, \pi]\) and \(\zeta\in[0, 2\pi/NFP]\). See Grid Dev Guide for some other considerations related to stellarator symmetry.
Let’s see the final computational domain!
[5]:
grid = LinearGrid(
rho=1,
theta=np.linspace(0, 2 * np.pi, 60),
zeta=np.linspace(0, 2 * np.pi / eq.NFP, 60),
sym=True,
)
fig = plot_3d(eq, "|B|", grid=grid)
fig = plot_3d(eq, "|B|", alpha=0.2, fig=fig)
fig.show()
DESC is a pseudo-spectral code, this means we evaluate the functions on given points, and don’t leave them in spectral form always. For force balance problem, we use a ConcentricGrid (see Grid Dev Guide for details). The force balance error \(\mathbf{J}\times \mathbf{B} - \nabla p\) is evaluated at those points.
[10]:
grid_points = ConcentricGrid(
L=5,
M=5,
N=5,
NFP=eq.NFP,
sym=True,
)
data = eq.compute(["X", "Y", "Z"], grid=grid_points)
x = data["X"]
y = data["Y"]
z = data["Z"]
fig = plot_3d(eq, "|B|", alpha=0.1)
fig = plot_3d(eq, "|B|", grid=grid, alpha=0.95, fig=fig)
fig.add_trace(
go.Scatter3d(
x=x, y=y, z=z, mode="markers", marker=dict(color="black", size=6, opacity=1)
)
)
fig.show()